
The Automated, No-Code Data Stack
Learn how Astera Data Stack can simplify and streamline your enterprise’s data management.

Data Lake vs Data Warehouse: Which Is Right for You?
To understand the difference between data lake vs data warehouse, it is important to understand the evolution of the technologies. Historically, databases served as structured repositories that excelled at storing and retrieving organized data. They operated within well-defined schemas, which made them suitable for transactional and structured data. However, as the volume, variety, and velocity of data exploded in the digital age, databases couldn’t keep up.
Then came in data warehouses that helped businesses by providing a more comprehensive and integrated approach to organizing and analysing data. Yet, they struggled with the agility needed to handle unstructured and semi-structured data effectively, which led to the introduction of data lakes, flexible and scalable solution designed for modern data challenges.
While data lakes are an upgrade to data warehouses in some aspects, they haven’t undermined the utility of data warehouses, which still play a pivotal role in data-driven organizations.
In this blog, we will discuss the differences between data warehouses vs data lake and what use cases are they best for.
What is a Data Lake?
A data lake is a storage system that allows you to store vast amounts of structured, semi-structured, and unstructured data in its raw, native format. Unlike traditional databases that require data to conform to a predefined schema (schema-on-write), data lakes use a “schema-on-read” approach, which means that in a data lake, data is stored as-is, without any enforced structure. This lack of schema restriction makes data lakes ideal for storing a wide variety of data types, including text, images, videos, log files, sensor data, social media posts, and more.
Businesses are increasingly adopting data lakes because of their highly scalability, both in terms of storage capacity and processing power and so organizations don’t need to worry about large and rapidly growing datasets, as is the case with traditional systems.
What are the Benefits of a Data Lake?
According to a survey, 69% of the respondents said that their companies had already implemented a data lake. Here are the reasons behind their increasing popularity apart from scalability:
- Cost-Effective Storage: Storing data in data lakes is often more cost-effective than traditional databases. For example, the increasing prevalence of the Internet of Things (IoT) has led to the emergence of time-series databases. These databases are equipped with specialized engines, tailored data models, and query languages that are finely tuned to handle time-series data efficiently. However, when confronted with vast volumes of sensor data, data lakes offer a more cost-effective substitute for time-series databases.
- Diverse Data Types: One of the most alluring factors of data lakes is that they are versatile in the sense that they can store structured, semi-structured, and unstructured data, including text, images, videos, and sensor data.
- Data Flexibility: Unlike traditional databases that require data to be structured upfront, data lakes allow you to store data as-is and apply structure when needed.
- Real-Time Data Ingestion: Today, everything is about real-time insights and data lakes support real-time data streaming and ingestion, which makes them suitable for applications that require immediate data processing and analysis.
- Machine Learning and AI: Data lakes are well-suited for machine learning and artificial intelligence (AI) applications, as they provide access to extensive, diverse datasets.
- Data Archiving: Data lakes can serve as a cost-effective solution for long-term data archiving and retention.
- Schema on Read: Unlike traditional databases with a schema on write approach, data lakes use a schema on read approach, which allows users to apply different schemas or structures as needed for analysis.
- Data Catalogs and Metadata: Data lakes often include data catalogs and metadata management tools, which help users discover, understand, and govern the data stored within the lake.
What is a Data Warehouse?
A data warehouse is a specialized database system designed to store, manage, and analyze large volumes of data from various sources to support business intelligence and reporting activities. Data warehouses primarily handle structured data, which is organized in tables with rows and columns. They often store historical data and are optimized to provide fast query performance. They also support complex data modelling and interactive analysis, which makes them instrumental for decision support and strategic planning.
The best part about a data warehouse is that they allow businesses to create data marts, specialized subsets of data for specific departments or business units. Data marts enhance decision-making at a granular level.
Read More: Data Warehouse Cost Estimation
Benefits of a Data Warehouse
- Support for Complex Queries: Data warehouses are optimized for complex queries and analysis, making it easier to answer intricate questions about the data.
- Improved Decision-Making: By providing a single, reliable source of data, data warehouses enable better and more informed decision-making at all levels of an organization.
- Data Consistency: They ensure data consistency and quality by integrating data from various sources, reducing errors and discrepancies.
- Historical Analysis: Data warehouses store historical data, allowing organizations to analyze trends and make forecasts based on past performance.
- Faster Queries: Their optimized structure and indexing enable fast query performance, reducing the time it takes to retrieve and analyze data.
- Support for Business Intelligence: Data warehouses serve as the backbone for business intelligence tools, aiding in data visualization and analytics for strategic planning.
Data Lake Vs Data Warehouse: Architecture
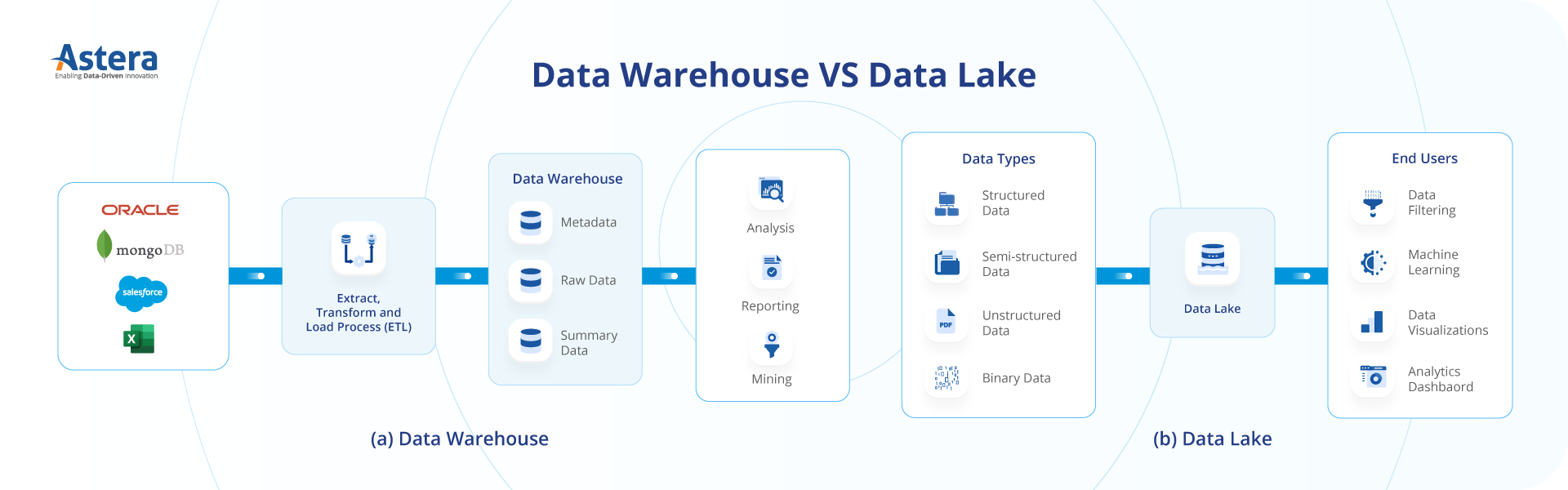
If you want to understand the difference between data lake and data warehouse, you first need to understand the difference between their architecture. Once you understand, how both are organized and how they function, it will become easier for you to choose between the two.
Data Lake Architecture
Data Ingestion Layer
The first layer is the data ingestion layer that ingests data from various sources. Data lakes usually offer two types of data ingestion:
- Batch Ingestion: With batch jobs, you can schedule to transfer and load data into the data lake at specified intervals.
- Real-time Ingestion: For real-time data streams, you can ingest data continuously and process as it arrives.
Storage Layer:
The second layer is the storage layer.
- Distributed Storage: Data lakes use distributed storage systems like Hadoop Distributed File System (HDFS) for on-premises environments or cloud-based storage solutions such as Amazon S3, Azure Data Lake Storage, or Google Cloud Storage. With these systems, you can store data at a large scale.
- Data Partitioning: Data is typically organized into partitions or folders within the storage system, which makes it easier to manage and query specific subsets of data.
Metadata and Catalog:
- Metadata Management: Metadata, which provides information about the data, is crucial in a data lake. Metadata includes details like data source, data structure, lineage, and quality. Metadata management tools help organize and make data discoverable.
- Data Catalog: A data catalog provides a user-friendly interface for discovering and understanding the data within the data lake. You can search for datasets and access associated metadata, helping them find the data they need.
Data Processing Layer:
- Data Transformation: Data lakes also come with provision for data processing and transformation as well. You can use frameworks like Apache Spark, Apache Hadoop, or cloud-based ETL services to prepare data for analysis.
- Data Integration: You can also use the data processing layer to integrate and combine data from various sources to create a unified view of the data.
Access and Analysis Layer:
- Data Access Tools: You can also access and analyze data using various tools, including SQL-based query engines, programming languages like Python and R, business intelligence tools, and data analytics platforms.
- Schema-on-Read: Data lakes support schema-on-read, meaning that data is read with the schema applied at the time of analysis. So, different users can apply different schemas to the same data.
Security and Governance Layer:
- Access Control: Robust access controls are essential to protect sensitive data. You can use its security features to implement appropriate permissions.
- Encryption: Data lakes often employ encryption to safeguard data both in transit and at rest.
Data Warehouse Architecture
Data warehouse architecture defines the structure and components of a data warehousing system. There are typically three major components in a data warehouse architecture:
- Data Sources:
- Operational Data Sources: These are systems like databases, CRM (Customer Relationship Management) software, spreadsheets, and various applications where an organization’s data originates.
- External Data Sources: Data can also come from external sources like market research, social media, or data providers.
- ETL Process (Extract, Transform, Load):
- Extract: Data is extracted from the various sources and brought into the data warehouse either through batch processing or real-time data streaming.
- Transform: The extracted data is cleaned, validated, and transformed to fit into a common format or structure, using data transformations and business rules.
- Load: The transformed data is loaded into the data warehouse, typically organized into fact tables (containing transactional data) and dimension tables (containing descriptive data).
- Data Warehouse Storage:
- Data Warehouse Database: Data warehouses use specialized database management systems (DBMS) designed for analytical purposes. Common types include traditional relational databases or newer columnar databases. The transformed and structured data is stored in here.
- Data Marts: Data marts are subsets of the data warehouse, often tailored to specific business units or departments. They are usually used for more focused analysis.
- Data Access Layer:
- Query and Reporting Tools: End-users interact with the data warehouse using query and reporting tools, such as SQL-based interfaces or BI (Business Intelligence) tools.
- OLAP (Online Analytical Processing): OLAP tools provide multidimensional analysis, which allows users to explore data in various ways, creating pivots, drill-downs, and complex analysis.
- Metadata Repository:
- Metadata is data about data. It includes information about the structure and meaning of the data stored in the warehouse. Metadata helps users understand and locate the data they need for analysis.
Data Lake Vs Data Warehouse: Differences
Now that you understand the data lake vs data warehouse architecture, here are some more differences between the two:
| Characteristic | Data Warehouse | Data Lake |
| Purpose | Designed for structured data, optimized for analytical processing, and reporting. | Designed to store both structured and unstructured data, including raw and semi-structured data for diverse analytics. |
| Data Structure | Stores structured data with a well-defined schema, often in tabular format. | Stores data in its native format, including raw, semi-structured, and structured data, without a predefined schema. |
| Data Ingestion | Involves a well-defined ETL (Extract, Transform, Load) process that structures and cleanses data before loading it into the warehouse. | Allows the ingestion of data in its raw form, without the immediate need for transformation. Transformation can be applied as needed. |
| Performance | Optimized for query performance, often using techniques like indexing and pre-aggregation for fast responses to SQL queries. | Prioritizes data storage over query performance. Query performance depends on how data is transformed and processed when queried. |
| Schema Evolution | Schemas are relatively static and changes may require significant effort and planning. | Allows for schema-on-read, enabling flexibility in accommodating changes to data without the need for upfront schema changes. |
| Data Type Flexibility | Primarily designed for structured data; may not handle unstructured data well. | Designed to handle structured, semi-structured, and unstructured data effectively. |
| Usage | Primarily used for structured data analytics, business intelligence, and reporting. | Used for a wide range of analytics, including advanced analytics, data science, machine learning, and data exploration. |
| Cost | Typically involves higher storage and query costs, as data is often duplicated and indexed for performance. | Often cost-effective for storing large volumes of raw data, but costs may increase with data processing and transformations. |
| Data Quality | Emphasizes data quality, consistency, and accuracy, often through strict data governance practices. | Offers flexibility and may require additional efforts to ensure data quality and consistency. |
| Examples | Examples include traditional data warehouses like Oracle Exadata, Teradata, or cloud-based services like Amazon Redshift. | Examples include cloud-based data lake solutions like Amazon S3 with AWS Glue or Azure Data Lake Storage with Azure Databricks. |
Use Cases
As far as the data lakes vs data warehouses use cases are concerned, data lakes are versatile and adaptable and can cater to a wide range of data types and analytics use cases, including advanced and exploratory data analysis. They can handle diverse data types and are well-suited for real-time data processing, and exploratory data analysis.
Data warehouses, on the other hand, are focused on structured data are essential for standardized reporting and business intelligence in various industries. Here are some of the prominent uses cases of both data warehousing and data lakes:
Data Warehouse Use Cases:
- Financial Reporting and Analysis: Data warehouses are widely used in the financial industry to store and analyze structured financial data. They mostly support activities such as budgeting, forecasting, and financial reporting.
- Retail Sales and Inventory Management: Retail organizations use data warehouses to analyze sales trends, monitor inventory levels, and optimize supply chain management.
- Customer Relationship Management (CRM): Data warehouses help organizations analyze customer data to improve customer satisfaction, identify sales opportunities, and target marketing efforts.
- Healthcare Analytics: The healthcare industry uses data warehouses for analyzing patient records, managing healthcare operations, and monitoring patient outcomes to enhance decision-making and patient care.
- Human Resources Analytics: Data warehouses support HR departments in tracking employee performance, managing workforce data, and making data-driven decisions for talent acquisition and retention.
- Logistics and Supply Chain Analytics: Companies involved in logistics and supply chain management use data warehouses to optimize routes, manage inventory, and track goods in transit.
- Manufacturing Process Optimization: Manufacturers use data warehouses for monitoring and analyzing production data, quality control, and equipment performance to improve processes and reduce costs.
- Energy Consumption and Utilities Management: Energy companies employ data warehouses to analyze energy consumption data, monitor infrastructure, and optimize resource allocation.
Data Lake Use Cases:
- Big Data and Machine Learning:
- Data lakes are ideal for storing and processing large volumes of diverse data used in machine learning models and data science projects, such as natural language processing and image recognition.
- Social Media Analytics:
- Organizations that analyze data from social media platforms to understand customer sentiment, track brand mentions, and improve marketing strategies also find data lakes more suitable.
- IoT Data Analysis:
- Data lakes are well-suited for handling data generated by Internet of Things (IoT) devices. They enable real-time monitoring and predictive maintenance in industries like manufacturing and smart cities.
- Genomic Data Storage and Analysis:
- Healthcare and research institutions store genomic data in data lakes for analysis and allow for personalized medicine and genomics research.
- Clickstream and Web Analytics:
- Companies use data lakes to store and analyze clickstream data, user behavior on websites, and online interactions to enhance user experiences and marketing efforts.
- Text and Sentiment Analysis:
- Data lakes can also be used to store text data from sources like customer reviews, emails, and documents for sentiment analysis, text mining, and content recommendation.
- Real-time Streaming Data:
- Data lakes ingest and analyze real-time streaming data, which is crucial for applications such as fraud detection, monitoring network traffic, and real-time decision-making.
- Archiving and Compliance:
- Organizations use data lakes for long-term data retention, meeting regulatory compliance requirements, and archiving historical data for legal and audit purposes.
Emerging Trends
There is always something new happening with data lakes and data warehouse technologies. Here are a few of the top trends:
Convergence of Data Lakes and Data Warehouses:
This is an interesting emerging trend as oorganizations are increasingly looking to bridge the gap between data lakes and data warehouses and converge them into a “lakehouse” architecture. A lakehouse aims to combine the strengths of both, so structured and unstructured data can coexist.
More Automation
Automated processes for managing data warehouses and data lakes will become more prevalent, which will make for businesses to quickly deploy and manage these technologies without manually configuring or using APIs to manage their systems.
Increased Use of Cloud Technology
Cloud technology is becoming more popular for storing and processing large volumes of data. Data lakes and warehouses that use cloud-based storage solutions can have a greater capacity than traditional on-site solutions. Thus, over time these technologies are going to become more cost efficient.
Faster Access Times
Data lake and warehouse technologies are becoming faster, so businesses can expect to see even larger performance benefits.
An End-to-End Solution for Modern Data Warehouse Development
Astera DW Builder offers a unified platform that you can leverage to streamline every aspect of their development process, from the initial collection and data cleansing to designing reporting-ready data models suited to your data governance requirements, course, and the deployment of your data warehouse in the cloud.
With ADWB, you don’t have to rely on a complex technology stack or experienced technical resources to get your implementation over the line. The product offers an intuitive drag-and-drop interface, supports speedy iteration, and works equally well with various source and destination systems. Contact our team to get started with Astera DW Builder today.



