
The Automated, No-Code Data Stack
Learn how Astera Data Stack can simplify and streamline your enterprise’s data management.

Automate PDF Data Extraction for Faster Insights
PDF (Portable Document Format) is an industry standard and one of the most widely used formats for presenting and exchanging information. Some common business documents that are shared in PDF format in the supply chain, business administration, and procurement industries include:
- Invoices
- Contracts
- Purchase orders
- Reports
- HR forms
- Shipping notes
- Presentations
- Product and price lists
While PDFs are great for exchanging information, extracting insights from data in these files can be difficult and tedious because data stored in PDF files is unstructured and can contain text and images.
Extracting unstructured data becomes even more challenging when you have to do it manually for each PDF file. This is where PDF scraping comes to the rescue. It helps extract data from PDF files in an automated way.

Manual PDF Data Extraction
The process of manually extracting data from PDFs is resource-intensive. It requires someone in the team to select the table and manually copy all the information in the PDF tables, which can lead to errors and long turnover times.
The process becomes even more difficult when hundreds of PDF documents is involved. Even if you have multiple resources for data retrieval, without data extraction automation, it can take days or weeks to get actionable information by manual data entry.
Manual Data Extraction: Cost vs. Efficiency
Let’s break it down in numbers to help you understand the cost when you extract info from PDFs. Imagine you have a dedicated analyst onboard responsible for pulling data from unstructured PDF documents and analyzing it. In that case, this is what the costs could be:
- The average salary of an analyst = 60,000 USD per year (US median wage)
- The average time spent by an analyst for data extraction from PDF documents, including data extraction, cleaning, and preparation per day = 70%
- The cost incurred by an analyst in extracting and preparing unstructured data from PDF = $42,000
With manual data extraction, most of the time and effort of the resource is spent on preparing data rather than analyzing it. Moreover, manual extraction is often inaccurate.
An alternate approach to this can be to outsource extraction. An enterprise-grade data extraction tool like Astera ReportMiner can be a cheap and efficient solution. Automating the PDF data extraction process with such tools reduces manual effort, speeds up data availability, and ensures data accuracy.
Automated PDF Data Extraction
Keeping the challenges of manual data extraction in mind, an ideal solution for businesses is to be able to parse all kinds of PDF documents with minimum human intervention through third-party tools. Here’s how PDF data extraction software can help your business:
- You can create and configure rules and formulas to automatically extract data from PDF to Excel. This reduces the time needed to manually search and copy/rekey the required information.
- You can extract data from images into text through built-in OCR engines without manually typing the data again. This reduces the chance of typos and other errors during extraction.
- You can automate data extraction from PDFs through AI. This is done by using AI to detect important fields and extract them automatically.
- You can automate the entire extraction pipeline and run it on a batch of PDF files to get all desired information in one go. This improves business efficiency and ensures the data is available as and when needed.
How to Automate PDF Data Extraction?
You can automate PDF data capture using one of these two methods. The first method is time-consuming, requires more resources, and has a higher tendency of trial and error. On the other hand, the second method is completely automated with the help of a data extraction tool.
1. Use Codes & Scripts
The first method is to write code or scripts for document processing and extract the desired information from PDF documents. However, this is not recommended for most businesses because it involves high complexity and dedicated developer resources. It often requires you to rewrite/modify code whenever the document structure changes.
2. Use Data Extraction Tool
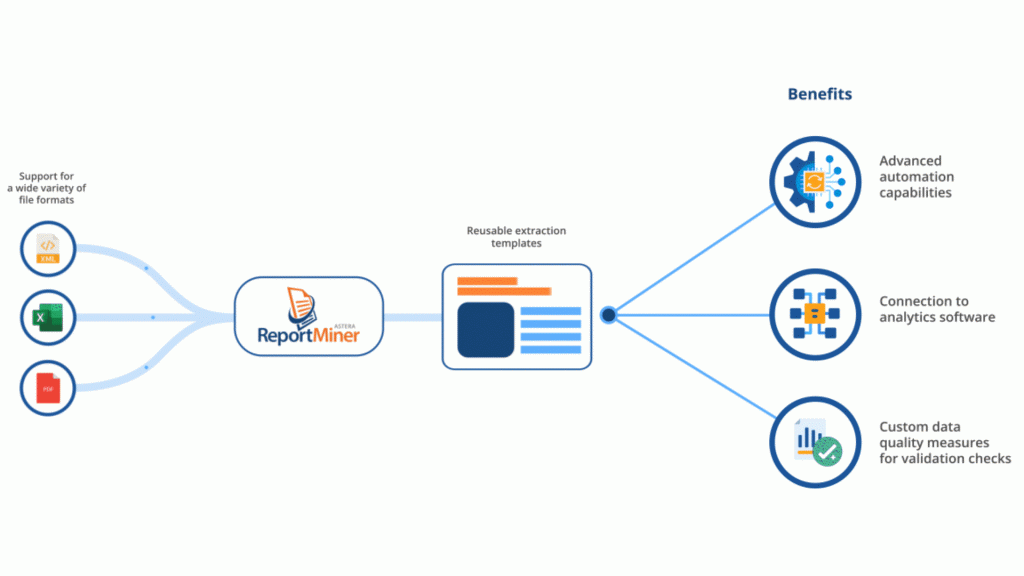
Use a tool to extract data from PDFs, such as ReportMiner. It is a data extraction automation solution with built-in support for auto data extraction. It provides a simple user interface that involves no coding. Hence, this is recommended for businesses that need to extract information quickly and accurately from high volumes of PDFs.
How ReportMiner Simplifies Automated PDF Data Extraction
Essential features you would need to automate data extraction from different types of PDFs include:
- Text-based PDFs: You can create an extraction template consisting of data regions and fields. These are sections and values that you want to extract. Through this, ReportMiner can read these documents and retrieve information.
- Scanned (image-based) PDFs: Not all PDFs consist of text data. Most PDF documents businesses use are scanned images (e.g., invoices). ReportMinner’s OCR (optical character recognition) capability can extract text data from images. Once you have run your scanned document through ReportMiner, it becomes similar to a text-based PDF and simplifies information capture.
- Form-based PDFs: Often, businesses have to deal with PDF forms, such as customer surveys or employee feedback. These PDFs are more structured than other types. You can make use of ReportMiner to extract important business data (such as customer information) and use it for reporting and analysis.
Once you design an extraction template in ReportMiner, you can reuse it to automate extraction from PDFs with similar layouts. The tool allows you to read PDF and Excel files from different sources, including the FTP server, email server, and unstructured systems.
If you prefer a faster solution, ReportMiner provides AI-powered data capture, removing the need to create templates. It allows you to simply extract all important fields in your pdf with just one click.
The extracted data can be further transformed and exported to a destination of your choice. Some popular options include Excel spreadsheets, databases, and .CSV files.
Start PDF Automated Data Extraction with ReportMiner
Businesses capture and deal with a variety of information in PDF documents, including transactional and reporting data. The challenge lies in extracting and structuring this information with reasonable accuracy and speed. This can be achieved by PDF data extraction automation through ReportMiner.
Download the trial version to experience how Astera ReportMiner can help you extract data from PDF files easily.



